
分布式计算的数据处理方式
分布式计算作为一种计算模式,其核心在于将大型复杂的计算任务分解成多个小任务,由分布在不同地理位置的计算机节点协同完成。这种方式不仅提高了计算效率,还增强了系统的可靠性。在分布式计算中,数据处理方式主要包括以下几种:
1. 批处理(Batch Processing):这是一种经典的数据处理方式,它将大量数据集中在一起,在一个时间点进行处理。Hadoop就是一个典型的批处理框架,它通过MapReduce模型来处理存储在HDFS中的大数据。
2. 流处理(Stream Processing):与批处理不同,流处理是一种实时数据处理方式。它可以立即处理数据流中的数据,适用于需要快速响应的场景。Apache Kafka和Apache Storm是流处理的常见平台。
3. 实时分析(Real-time Analytics):这种方式强调在数据生成的同时进行分析,以便快速得出洞察和决策。Spark Streaming和Flink是支持实时分析的流行框架。
4. 分布式数据库(Distributed Databases):分布式数据库通过在多个节点上分散存储数据,来提供高可用性和可扩展性。Cassandra和MongoDB是两个著名的分布式数据库系统。
5. 云计算服务(Cloud Computing Services):云服务提供商如AWS、Azure和Google Cloud Platform,提供了一系列分布式计算服务,包括存储、数据库、机器学习等。
免责声明:以上内容(如有图片或视频亦包括在内)均为平台用户上传并发布,本平台仅提供信息存储服务,对本页面内容所引致的错误、不确或遗漏,概不负任何法律责任,相关信息仅供参考。
本站尊重他人的知识产权、名誉权等法律法规所规定的合法权益!如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到qklwk88@163.com,本站相关工作人员将会进行核查处理回复
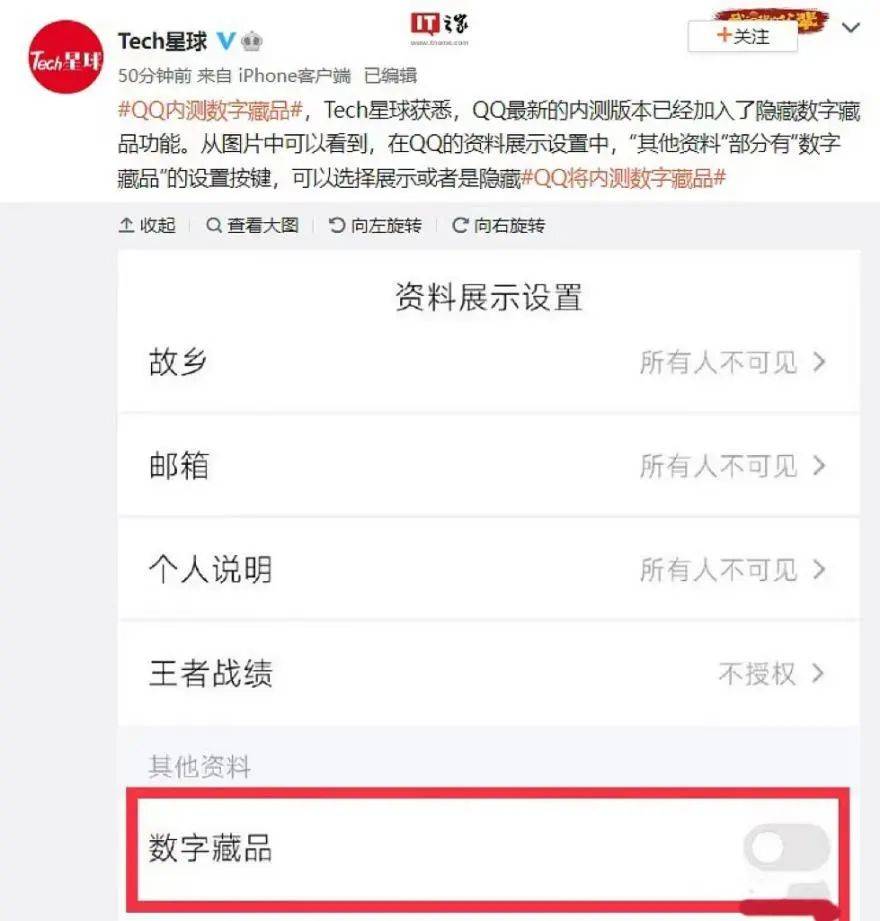
暂无评论内容